
Challenges in implementing ant colony optimization
Here are the more technical details of ACO implementation are discussed. The reasoning behind it and the conclusion are in a separate post.
Implementation
I started off with an existing app that had a CRUD scaffold and added import for orders and encountered a few challenges, none of which were really substantial.
Geocoding addresses
In order for any routing to work a graph of edges and vertices needs to be built. The weight of each edge is the distance between nodes. To calculate distance the order addresses had to be geocoded. I had used the geocoder gem before and it isn’t great for addresses. Google Maps works well but it isn’t free so it isn’t suitable for an MVP.
Instead, I decided to route to post codes. Geocoder worked well enough for post code coordinates. For a start, routing between post codes should be good enough.
Getting a list of post codes
It wasn’t exactly straight-forward but in the end I got a list of Klang Valley post codes used by DHL ecommerce. Then, I could get the coordinates for all them in bulk.
s = Geocoder.search("#{post_code}, Malaysia")
begin
data = s.find{|x| x.data['address']['country'] == 'Malaysia'}.data
self.lat = data['lat']
self.lon = data['lon']
self.save
rescue StandardError => e
puts "Not found."
endUn-geocodable post codes and enclaves
There were many post codes that couldn’t be found. For example, JPJ Shah Alam uses the post code 40620. That number is just for the JPJ building. Geocoder understandably couldn’t find those. There were also ones that seem to have been allocated but not in use, for example 40569.
To fix this, the first thing that could be done is manually getting the coordinates for post codes that are missing.
But I also added a replacement attribute for each post code. If the replacement existed, those coordinates would be used. So, from the example above, 40200 would be as the replacement for 40620 because it entirely encircles it. It’s easier and quicker to just select a replacement instead of looking for coordinates.
Calculating the distance
My first choice was to use Google Distance Matrix for distances. However, it costs $5 per 1000 elements and doesn’t allow caching or storing. At around 200 valid post codes, each run might cost $200. This made it prohibitively expensive.
MySQL (and PostGIS) have ST_Distance_Sphere that returns straight line distance using the Haversine formula. On Earth, for nearby coordinates, that’s accurate enough.
The main down side of this approach is that it doesn’t take into account roads and traffic but that level of optimization isn’t needed yet.
At this point, there are nodes and the ability to calculate distances which means that nearest neighbor can be implemented.
And it can be easily done with a scope in the post code model:
scope :nearest, -> (post_code) {
select("internal_post_codes.*, ST_Distance_Sphere(point(#{post_code.lon.to_s}, #{post_code.lat.to_s}), point(lon, lat)) as distance").
where("internal_post_codes.id <> ?", post_code.id).
where("lat is not null and lon is not null").
order("distance asc").
first
}I also generated a matrix with all the post code pairs and their distances but the performance gain was negligible. Its schema just looked like this:
origin_id :integer
destination_id :integer
distance :decimal(15, 4)
ACO library
Next, I had to find a suitable ACO library. I quickly found acopy that looked simple and actively maintained. It also had clear docs.
Generating TSP file
acopy can use TSP files to load the graph. I was not familiar with the format but found a list of samples. There was one that used geographic coordinates (burma14) and another had distances (bayg29). I first tried with the coordinates example, but couldn’t get that to work. But, I managed to figure out the distances format (minus the display section.) In retrospect, I suspect that the issue with the distances format might also be the display section.
Here’s a generated sample for one with 15 destinations:
NAME: Delivery
TYPE: TSP
COMMENT: Delivery
DIMENSION: 15
EDGE_WEIGHT_TYPE: EXPLICIT
EDGE_WEIGHT_FORMAT: FULL_MATRIX
DISPLAY_DATA_TYPE: TWOD_DISPLAY
EDGE_WEIGHT_SECTION
0 32787 25503 39896 34394 14444 48481 19330 4947 23882 20536 16880 38091 18797 19960
32787 0 8206 15580 4426 18718 23369 20537 28275 9032 14079 16237 8575 14178 26507
25503 8206 0 16518 11629 12481 25367 12519 20761 2495 5877 10268 12726 8299 18629
39896 15580 16518 0 19433 28675 8885 21620 34949 18982 19649 26659 7792 24773 25236
34394 4426 11629 19433 0 19979 26627 24148 30183 11668 17284 17518 11902 15615 30248
14444 18718 12481 28675 19979 0 37559 13875 10593 10323 9675 2489 25115 4542 18765
48481 23369 25367 8885 26627 37559 0 29716 43540 27813 28451 35540 14828 33642 32458
19330 20537 12519 21620 24148 13875 29716 0 14566 12958 7200 13707 22123 13429 6187
4947 28275 20761 34949 30183 10593 43540 14566 0 19281 15637 12854 33257 14599 15954
23882 9032 2495 18982 11668 10323 27813 12958 19281 0 5798 7996 14797 5960 19146
20536 14079 5877 19649 17284 9675 28451 7200 15637 5798 0 8365 17687 7268 13380
16880 16237 10268 26659 17518 2489 35540 13707 12854 7996 8365 0 22784 2083 19120
38091 8575 12726 7792 11902 25115 14828 22123 33257 14797 17687 22784 0 20726 27146
18797 14178 8299 24773 15615 4542 33642 13429 14599 5960 7268 2083 20726 0 19184
19960 26507 18629 25236 30248 18765 32458 6187 15954 19146 13380 19120 27146 19184 0
The order of the nodes matters because acopy returns an ordered array of indexes of nodes as specified here.
Running it from rails
Once I figured out the format, I could generate it from rails and run the script. Just to get it running, I used backticks and ran in the main thread:
sequence = JSON.parse(`cd /home/regac/code/kv-aco && pipenv run python main.py`)The result is an array of indices as in the TSP file.
At this point, the MVP is effectively complete.
Run time
Results were garbage for 10 and 30 ants. 50 ants took about 10 minutes to run and had improved results. 100 ants took about 30 minutes with better results. And 300 ants took about an hour with what looked like good results.
I don’t trust these times however, because I was using the computer while the script was running, so they’re indicative at best.
The balance between the number of interations and runtime could be fine-tuned over time relative to the number of locations.
Comparison
To test the gains I got a real list of a few hundred orders that ended up being 89 unique post codes. I then ran it with with different number of ants and compared the results to nearest neighbor calculations.
10 ants
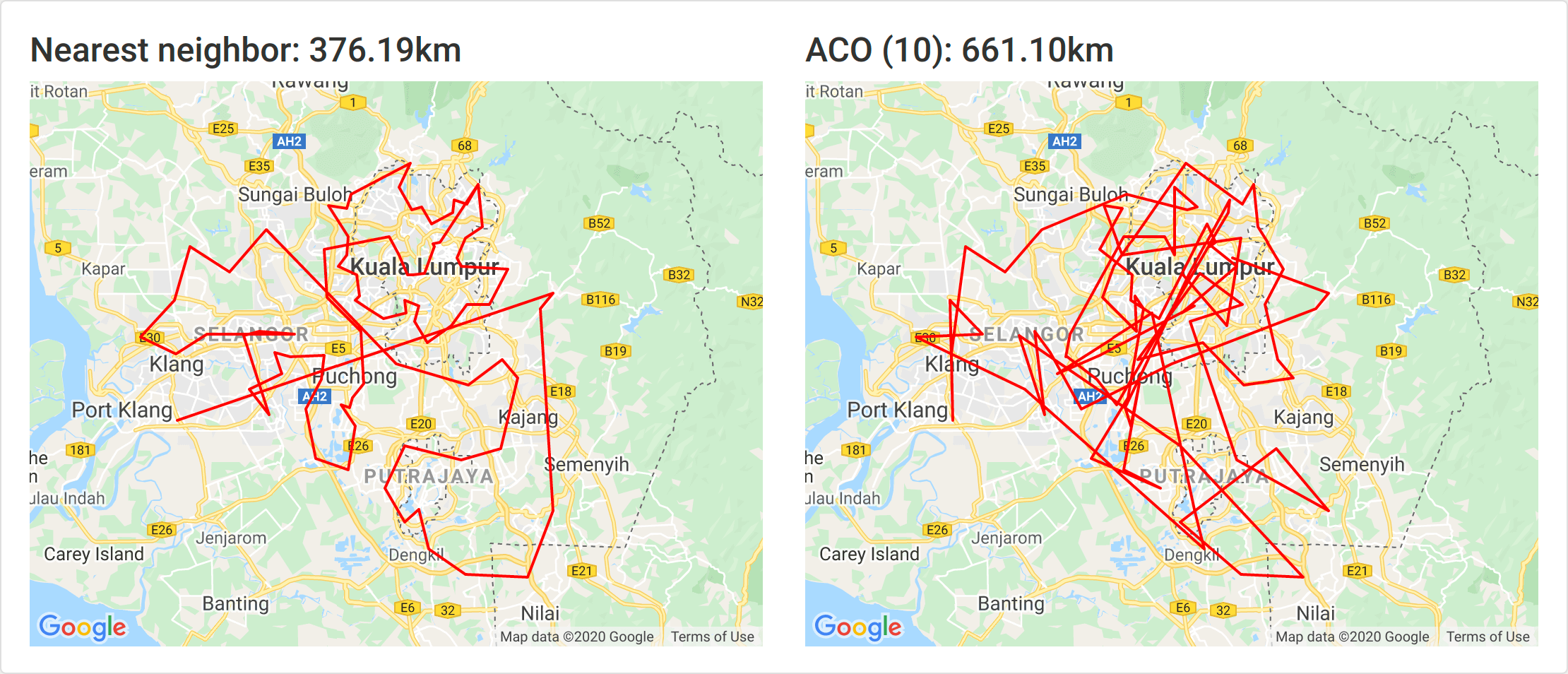
As with all the Klang Valley post codes, 10 ants is not sufficient. This is almost definitely due to the number of nodes.
50 ants
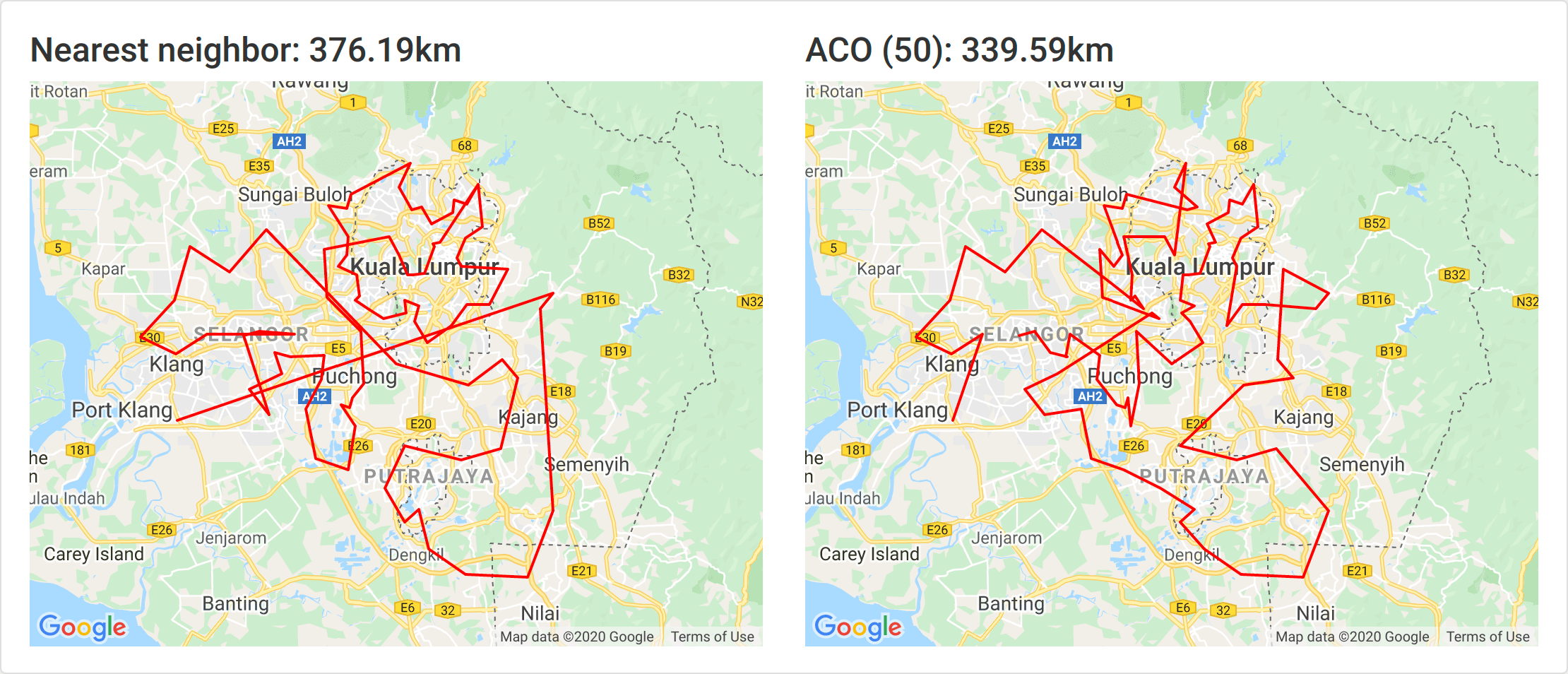
At just 50 ants we immediately have a solution that is 10% better than nearest neighbor.
100 ants
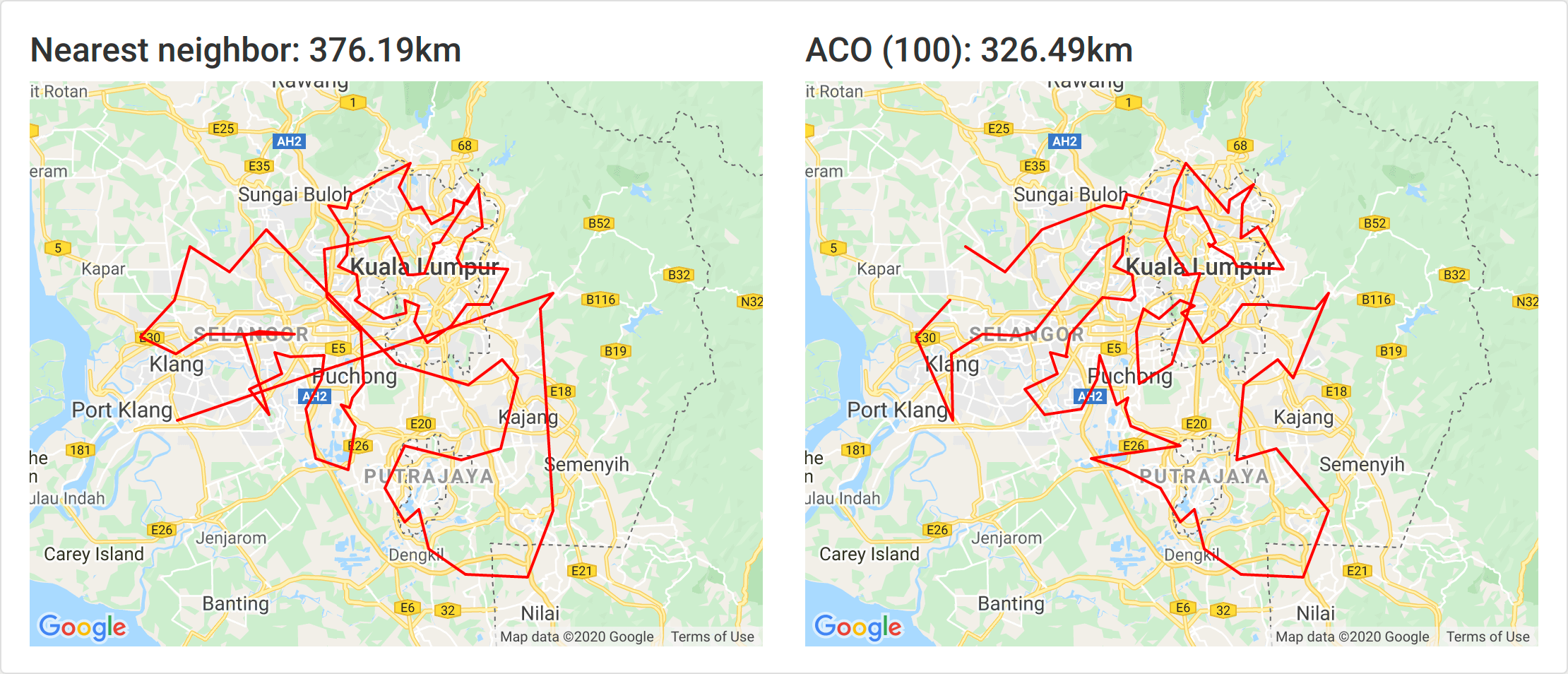
At 100 ants, the solution is 13% better.
300 ants
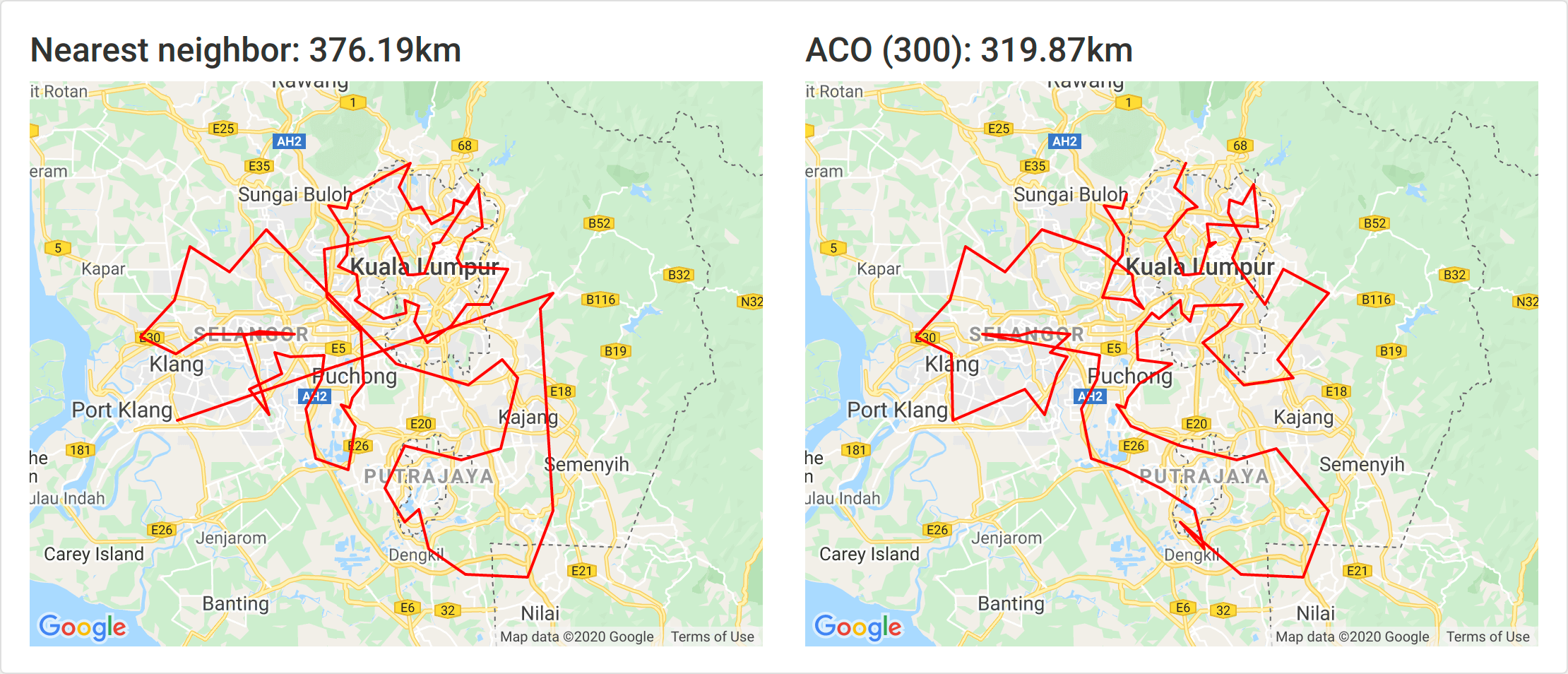
At 300 ants the solution is 15% better and it ran for 13 minutes.
500 ants
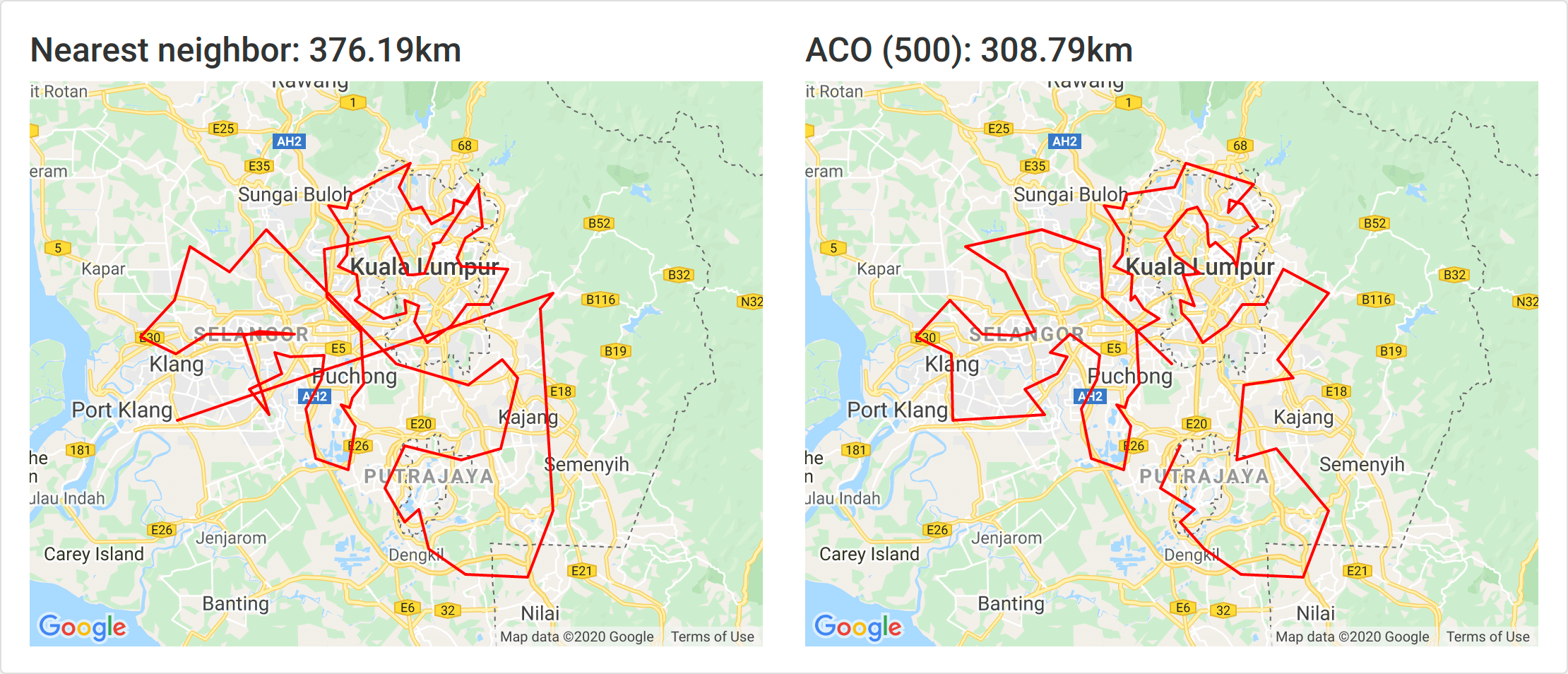
500 ants took about 20 minutes and yielded an 18% improvement.
1000 ants
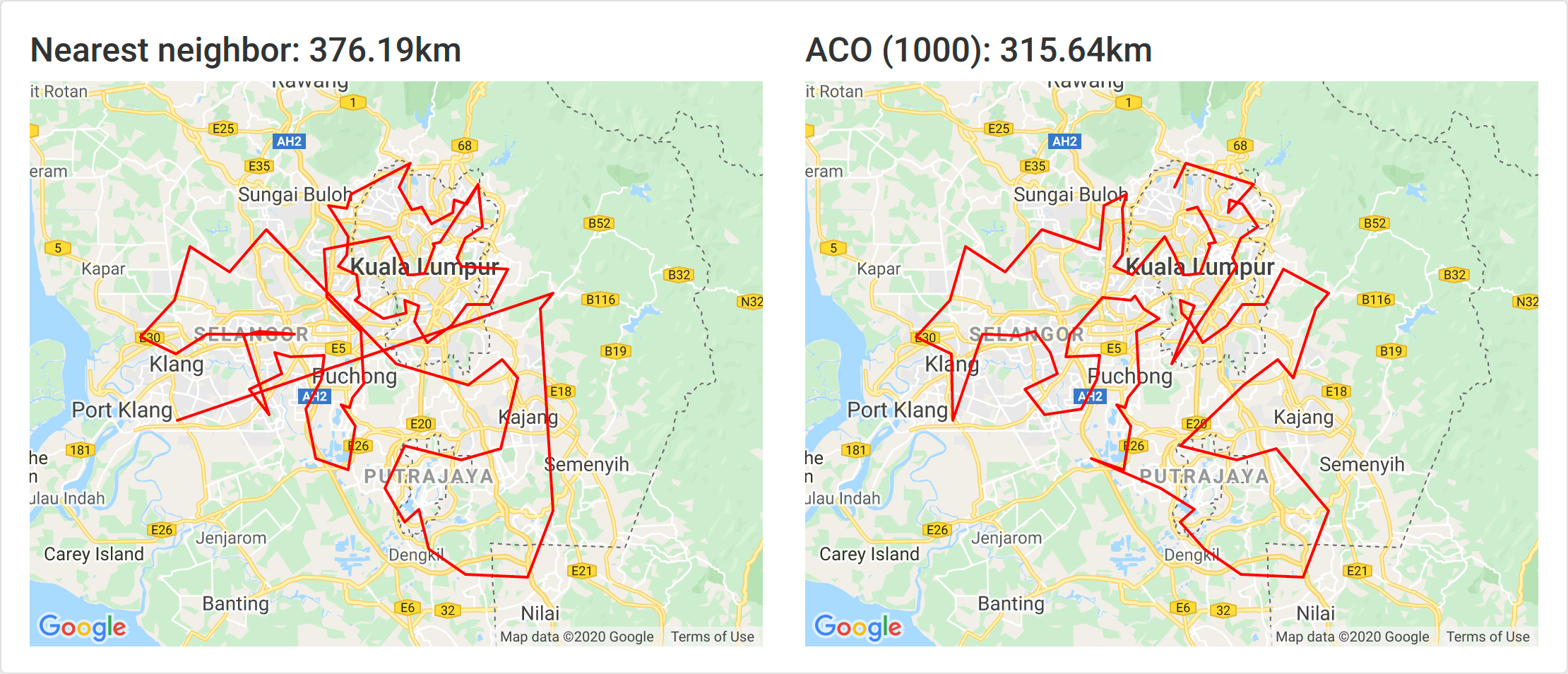
1000 ants took around 45 minutes and yielded an 16% improvement.
2000 ants
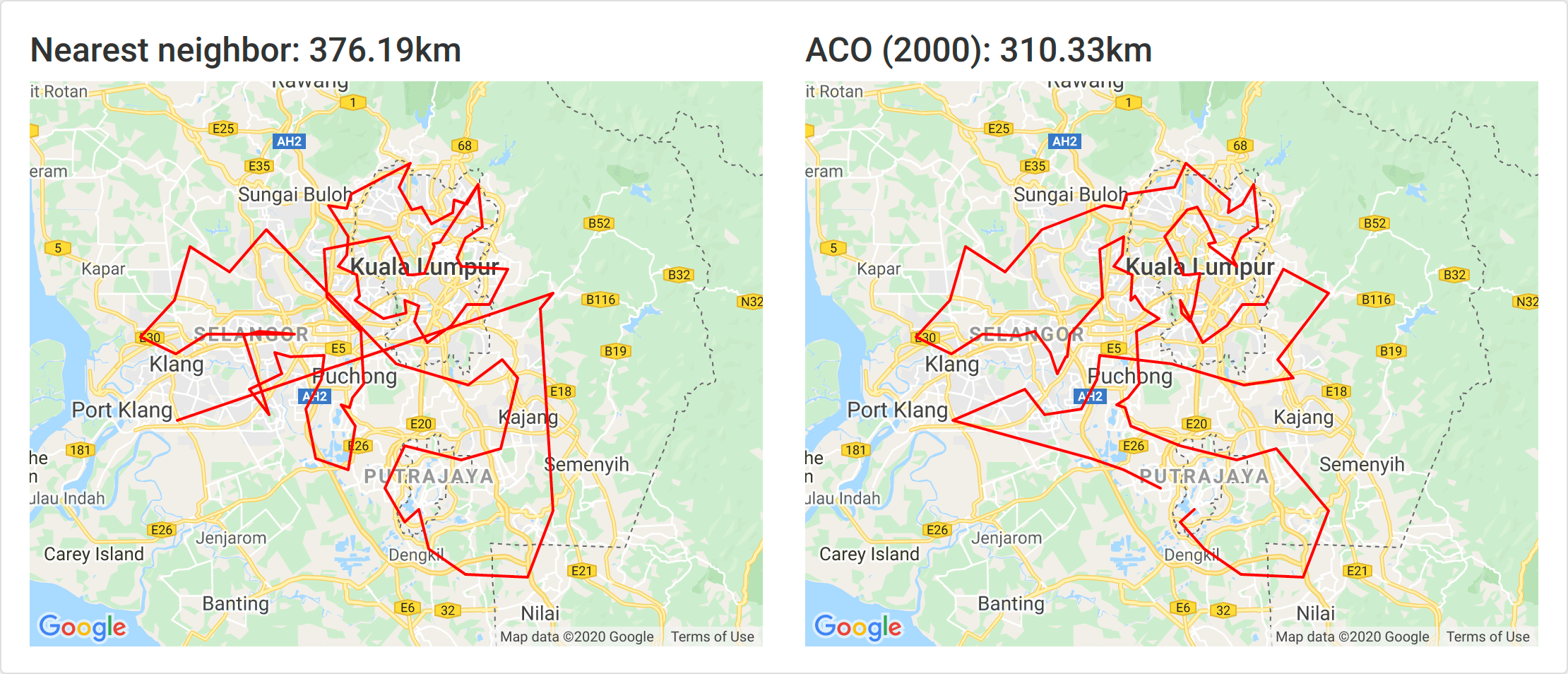
2000 ants took around an hour and 20 minutes and yielded an 17% improvement.
Interestingly the 500 ants generated the best result. Since ACO uses probabilities so there is some randomization a greater number doesn’t strictly guarantee better accuracy.
From this quick test, about 6× the number of nodes looks sufficient for a solution that’s significantly better. Even a 15% improvement yielded by 300 ants is great.
Future improvements
Because this experiment took about a day to get working it’s very rough around the edges and there are several things that could be done to improve it and get it more production ready.
Have the ACO run in background
This is the most obvious and urgent improvement. Instead of executing a script in the main thread, it needs be done in a background worker.
Make the ACO a service
The proper way would be to make the ACO a service in itself that would have a series of coordinates passed in and it returns the optimized route.
This would be much better than the current implementation of generating TSP files.
Calculate delivery schedule for all orders
Instead of having the user create a new delivery and upload orders to it, it would be better to have the user simply upload orders and then calculate the route for all pending orders.
That would allow some more fine tuning such as:
- Prioritizing post codes: closer, more frequent and “on-the-way” post codes could take precedence.
- Grouping post codes into areas: clustering post codes by how often they’re visited and introducing a threshold before a delivery is performed would improve processing time for the rest allowing for more accurate routes.
Both would also improve efficiency by delivering to the far nodes less frequently.
Automate order import
Instead of having the user upload orders the system should import them directly. Ideally an API exists but it is possible to automate export to Excel or CSV and the subsequent import.
Route within post code and use Google Distance Matrix
This would start entering the realm of marginal gains.
Once the post codes are all routed efficiently, we can focus on routing inside the post codes. This would require the Google Distance Matrix but with significantly less elements generated.
Following that, real traffic conditions between post codes can be taken into account.